Imagine you’re a historian of the 21st century living and working in the 23rd century. You have an archive containing millions of documents related to an event (say, the Arab Spring), but you cannot read them—all you see is a number. It’s the ID number of a tweet, but only the number was saved, and the code no longer exists to display the content.
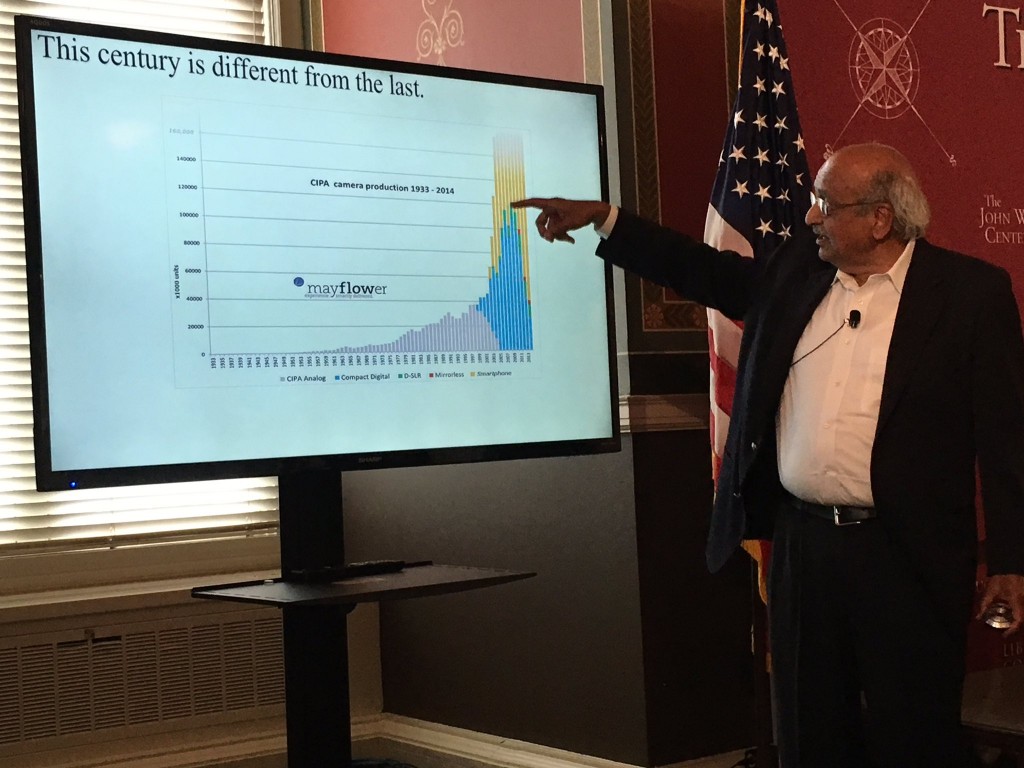
Ramesh Jain uses the example of the move from analog to digital cameras to smartphones to demonstrate that “This century is different from the last.” Photo by Shawn M. Jones via Twitter
This was the hypothetical example posed by Katrin Weller (Leibniz Inst.) to demonstrate the importance and complexity of archiving today’s digital artifacts. Rather than record our lives on paper, we use e-mail, send Facebook messages, tweet, and leave comments on our favorite blogs. Websites have become our chief sources of information, and online games a prominent feature of human socialization. Which of these digital artifacts will be available for historians looking to decipher our lives years from now? What should we save, how should we save it, and what ethical problems arise from the act of saving electronic records? These were the central questions debated at “Saving the Web: The Ethics and Challenges of Preserving What’s on the Internet,” a one-day symposium hosted by Dame Wendy Hall (Univ. of Southampton) at the John W. Kluge Center at the Library of Congress on Thursday, June 16, 2016. The symposium featured tech pioneers such as Vint Cerf, considered to be one of the “fathers of the Internet”; James Hendler, creator of the semantic web; and Ramesh Jain, multimedia and social networking entrepreneur. Archivists, librarians, and humanists also featured prominently, showing that above all, the effort to preserve our digital cultural heritage will be both collaborative and interdisciplinary.
Cerf highlighted some of the challenges of preserving what he refers to as “digital vellum.” He noted that preserving digital content, such as text, music, and video, as well as interactive content, such as games, would require not only saving the content itself but the source code and hardware used to interact with it. Websites, too, pose their own challenges—links (an integral feature of our 21st-century record) constantly break down and content is always being updated. Cerf pointed to the Internet Archive’s Wayback Machine, which takes snapshots of web pages and has an internal link system that preserves networks of pages, as a useful model for dealing with this problem.
A screenshot of the 1984 Synapse Software Corporation’s Alley Cat on the Internet Archive WayBack Machine. The game ran on MS-DOS and was a childhood favorite of the author of this post.
In addition to the technical hurdles, Cerf noted the importance of “preservation on purpose” rather than by accident. In fact, one of the biggest challenges digital archivists face is deciding what to save. Cerf observed that a digital object that could be relevant in 200 years might not look important now. Philip Napoli (Rutgers Univ.) argued that with current news archiving practices, it would be easier for future historians to study local newspapers from 1940 than from 2015. He made the case for archiving local news websites, which can provide invaluable insights into local economy, culture, education, etc. Abbie Grotke, who heads the Library of Congress Collections with Archived Web Sites, raised the issue of determining not only what content to archive, but also how often to archive it.
Of course, deciding what to keep is itself an act of interpretation that will influence the histories written in the future. Although Jefferson Bailey (Internet Archive) pointed out that the web allows for “unprecedented plurality of representation within the historical record,” in order for that to power representative histories, we need to archive representative material. Which websites do we save? Whose tweets? Speakers were highly aware of the archival act as a form of advocacy. Abbie Grotke provocatively raised the possibility of archiving websites in China before the government could retroactively censor them—in such a case, the archival act would preserve those silenced voices for the future. Another different but related ethical issue was the issue of privacy: when someone tweets, posts on Facebook, or leaves a comment on a web article, does that person have the “right to be forgotten”? Should they be informed and allowed to withhold their content from being archived? This too, impacts the wholeness of the historical record. Historians, who work to revive underrepresented voices and untold stories as well as to faithfully represent the past, are well suited to identify the materials needed to reconstruct these narratives, and should join conversations on the ethics of what we save.
Even if we’ve saved valuable and representative digital content, however, it will be useless to future historians if there isn’t a system to help them find what they are looking for. Metadata—data that provides additional, contextual information about digital content—is central to this endeavor. As James Hendler (Web Sciences Trust) and Philip E. Schreur (Stanford Univ.) discussed, keywords are a predominant way of tagging and searching for data, but how do we navigate the problem of different people thinking about the same keyword differently, or of keywords’ associations changing over time? (An example raised during discussion was that of cats and dogs, which were filed under “Agriculture and Related Industries” in the Dewey Decimal System, but would now be considered as pets by a majority.)
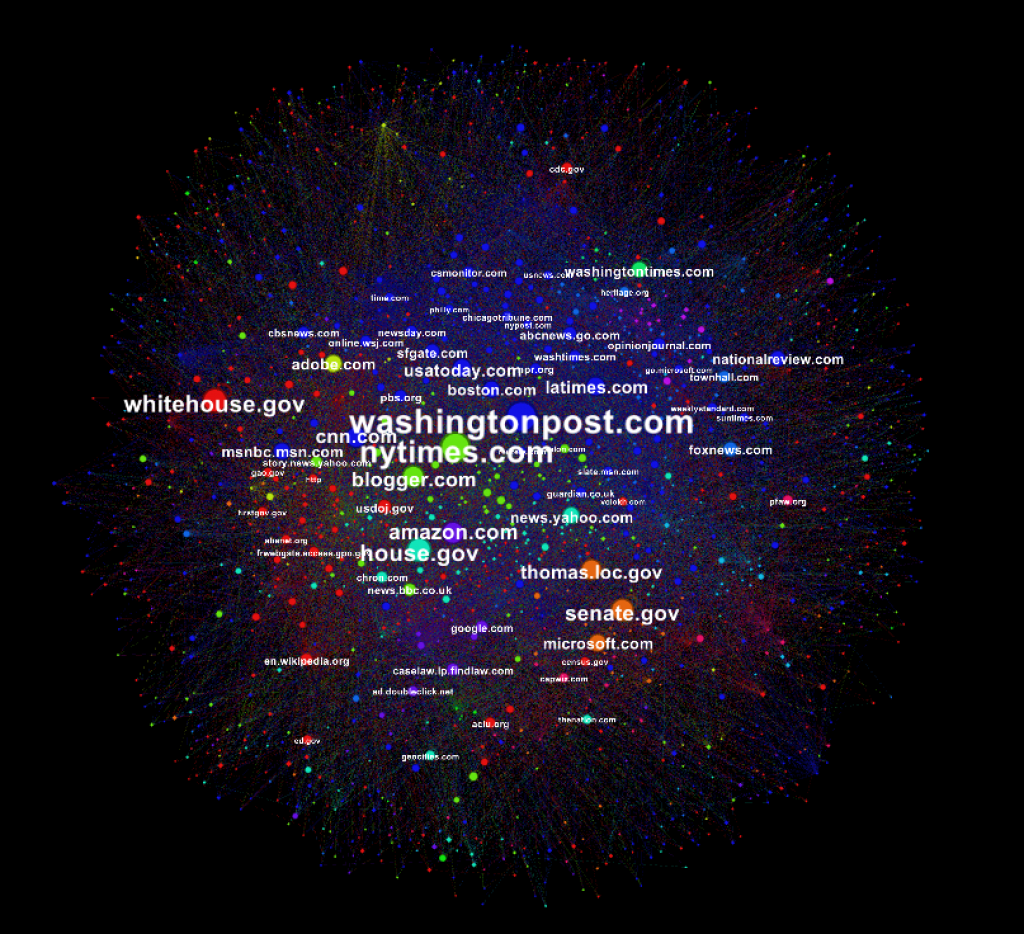
A network visualization of links between web domains publishing content on the 2005 nomination of Supreme Court Justice Alito. Generated by Ian Milligan, in collaboration with the Supreme hackathon team. Data provided by the Library of Congress Web Archive
Historians are already considering how to use the burgeoning digital archive. As Ian Milligan (Univ. of Waterloo) reflected, “Historians are moving from scarcity—where we used to have no information about the past—to abundance, where we have too much.” During the symposium, participants from a two-day “datathon,” Archives Unleashed 2.0, which was dedicated to understanding and creating solutions for handling this abundance, presented collaborative projects demonstrating what big-data approaches such as text mining and network visualization could reveal about large datasets. (See Ian Milligan’s blog on using big-data methods to study the nominations of Justice Alito and Justice Roberts.) In order to think effectively about how to save something, we need to have an idea of how we want to use it; explorations like these can help.
Why do we want to preserve the Internet? For historians, the answer is perhaps self-evident: it is the record the present is leaving for the future. Without advocates, however, the institutions and individuals who are needed to help preserve digital content might not necessarily be convinced of its value. Large-scale, long-term web preservation will require buy-in from the government, cultural institutions, the private sector, and the public. Richard Price of the British Library recommended a variety of approaches in advocating for Internet preservation, including preparing digital exhibitions alongside physical ones, holding public conversations, publishing op-eds about digital archiving, and “being poetic”—it’s much more compelling to a wider public to talk about Internet preservation as “time travel” than delving into the standardization of metadata. Price also emphasized advocacy through networking: historians need to participate in conversations about web archiving, get to know those who are involved in making it happen, and make the case for materials that they believe should be saved.
Ultimately, a common thread that echoed throughout the day was the need for collaboration in this massive effort. As Hall pointed out, those who have data must work together to enable their databases to communicate; she enjoined those in the room with datasets (listen up, digital historians!) to share them with Web Observatory, an initiative to locate datasets across the globe and to look for ways of searching them and using their data to inform industry and policy decisions. We also need collaboration among experts from vastly different fields. Those who understand the technical requirements, possibilities, and implications for massive digital record storage need input from historians in determining what to keep and why, organizing these records, and considering the human implications of those decisions.
Many thanks to those who helped with this piece via Twitter, including Meaghan Brown (@EpistolaryBrown), James Hendler (@jahendler), Shawn M. Jones (@shawnmjones), Ian Milligan (@ianmilligan1), Lee Rainie (@lrainie), and Jason Scott (@textfiles), for their generous input on the wiles of the Dewey Decimal System and assistance with images.
The Library of Congress will be posting video of the entire conference online in the coming weeks. Attendees live-tweeted the symposium to #SaveTheWeb; for a digest, see the blog post on the event.
Referenced Projects and Initiatives
Archives Unleashed 2.0: Web Archive Datathon, June 14–15, 2016: A series of projects produced collaboratively during a two-day datathon in which professionals experimented with big-data approaches to using the information in digital databases
Collections with Archived Websites (Library of Congress): Curated collection of 90 websites (22 publicly accessible) that are routinely crawled and archived
The Computer History Museum: A museum in Mountain View, California, that “seeks to preserve a comprehensive view of computing history”
University of Maryland Cyber Infrastructure for Billions of Electronic Records (CI-BER) “DataCave”: A testbed of digital records the DCIC is using to experiment with solutions to archiving a variety of digital content
The Handle System: Robert Kahn (Corporation for National Research Initiatives) was unable to attend to deliver the second keynote address, but Vincent Cerf delivered his notes on the Handle System, used to organize digital object identifiers, which then enable access to the digital content
Internet Archive WayBack Machine: Takes snapshots of web pages and has an internal link system that preserves networks of pages
National Science Foundation Data Infrastructure Building Blocks (DIBBs): A funding program supporting interdisciplinary research and innovation in data management
The Networking and Information Technology Research and Development Program and the NITRD Supplement to the President’s FY17 Budget: Speaker Richard Marciano noted two important features in this supplement: first, its valuation of digital preservation broadly, and second, the need for trust in this endeavor
The Olive Executable Archive: Project that mimics old hardware in order to run interactive digital content that used it
Places and Spaces: Mapping Science (Cyberinfrastructure for Network Science Center): Katy Borner, curator of this collection, presented it at the symposium, using it to demonstrate the powerful visualizations that could be produced by using large datasets
Schema.org: “Collaborative, community activity with a mission to create, maintain, and promote schemas for structured data on the Internet, on web pages, in email messages, and beyond” (schema.org)
Web Observatory (Web Science Trust): An initiative to locate datasets across the globe and research ways of searching them and using their data to inform industry and policy decisions
This post first appeared on AHA Today.
Tags: AHA Today Archives Digital History
Comment
Please read our commenting and letters policy before submitting.





